Podcast
Menu
Rechercher

High-Tech
Google dévoile un nouvel outil pour mesurer la fiabilité des chatbots... Gemini 3 Pro arrive...
Google a présenté la FACTS Benchmark Suite, un outil conçu pour évaluer la précision factuelle des chatbots d’intelligence artificielle. Selon les résultats publiés, Gemini 3 Pro arrive en tête avec un score de 69 %, devant ChatGPT, Grok et Claude.
Vous créez des podcasts ?
Créez vos podcasts directement sur Lykhubs ou référencez simplement les flux dans notre annuaire pour les diffuser au sein de la communauté.
En savoir plus

Musique
Awards HQ: Starry FYC Events With Reba McEntire, Baz Luhrmann and Sofia Coppola Helped Set the...
Welcome to Variety Awards HQ! Your weekly command center for the Oscars race. It’s Dec. 8, 2025, and we’re deep in the thick of it. The past seven days have been a whirlwind of major awards season benchmarks, and if anyone thought this year’s race would follow a predictable...

High-Tech
L’ultra-fluide moniteur QD-OLED de Samsung (27″, 500 Hz) sort de son Odyssey en...
Vous avez déjà une machine qui explose les benchmarks et arrache les FPS comme si c’était un sport olympique. Il ne manque qu'un moniteur capable d’avaler 500 Hz sans broncher. Oui, cinq cents. La prouesse est signée Samsung, avec son Odyssey G6, le premier de sa...

High-Tech
Samsung Galaxy Z TriFold : le premier benchmark dévoile des performances décevantes
À quelques jours de son lancement, le Samsung Galaxy Z TriFold affiche des résultats Geekbench inférieurs aux standards de sa puce Snapdragon 8 Elite, laissant présager des compromis techniques liés à l'intégration matérielle de ce nouveau format pliant. L’article...


Musique
‘Ramayana’ Aims to Set New Global Benchmark for VFX, Director Reveals at WAVES Film...
Nitesh Tiwari said his upcoming “Ramayana,” described as India’s most expensive film, is being built to deliver a level of visual scale and craftsmanship that can stand alongside the world’s top VFX productions, telling a WAVES Film Bazaar audience that the epic demands...

High-Tech
Le meilleur modèle pour coder a déjà changé, Claude Opus 4.5 détrône déjà ...
Six jours après Gemini 3 Pro de Google, qui a battu tous ses rivaux dans la quasi-totalité des tests, Anthropic dévoile Claude Opus 4.5, son nouveau grand modèle de langage qui promet de réparer le code des développeurs mieux que personne. Dans les benchmarks sur ce critère,...


High-Tech
Google Antigravity : ce n’est pas un OS pour développeurs, mais ça y ressemble...
Tout le monde regarde Gemini 3 et ses scores délirants sur les benchmarks. C'est une erreur. La véritable annonce de Google aujourd'hui s'appelle Antigravity. Ce n'est plus un chatbot, c'est un environnement où l'IA a les mains libres sur votre terminal et votre navigateur. Et ça...

High-Tech
Les benchmarks d’IA sous le feu des critiques
Une récente étude met en lumière de graves lacunes dans les tests de sécurité des intelligences artificielles, soulignant que ces failles pourraient compromettre la fiabilité et la sûreté des systèmes automatisés à grande échelle.
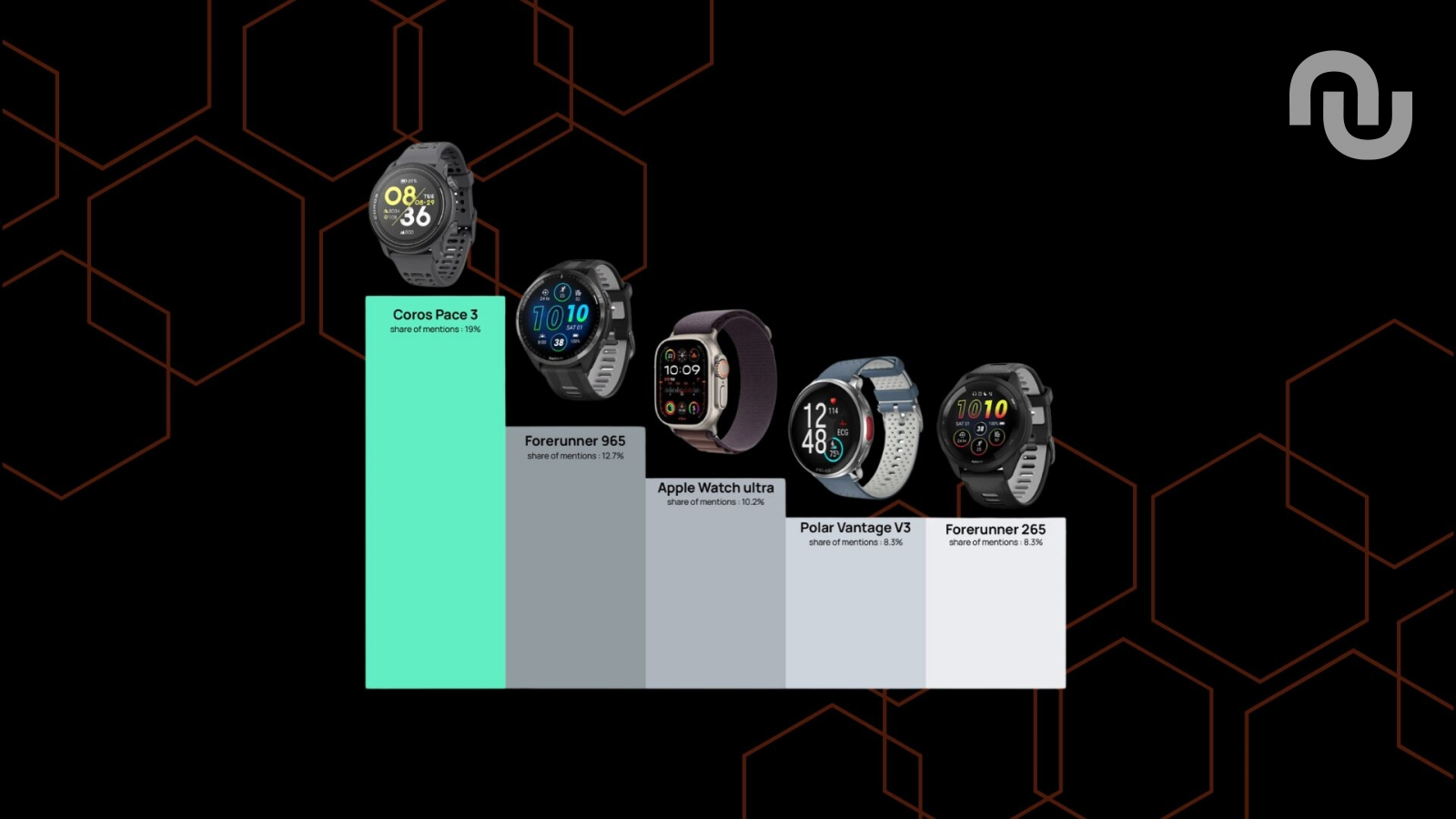
High-Tech
Géniales sur les Mac, nulles sur les montres : ce que les IA recommandent comme produit tech (et...
Grâce à l'outil de benchmark IA Whiteship, Numerama a obtenu le classement des produits les plus cités sur des requêtes conso courantes liées à la tech. Est-ce que vous pouvez faire confiance à ChatGPT, Gemini, Mistral ou Perplexity avant de choisir votre prochain produit ?...